Exchange Monitoring: DAG Best Practices

On-premises Exchange servers are still a thing, and with future versions of Exchange coming...


With some small and medium size businesses unable to afford larger, enterprise solutions for Exchange monitoring, we will explore the local tools built into Exchange to help you leverage Exchange CAS monitoring from within the Exchange program itself. This article is meant as an overview detailing the built-in tools available and may require more independent reading and learning before making any changes to your organization’s solution.
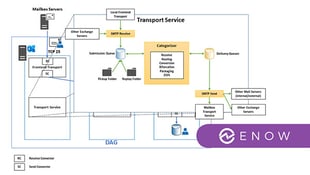
Exchange Server 2019 includes all server roles into one main role, the Mailbox server role. This feature was included in Exchange 2016 as the Client Access Server role is no longer available as a separate installation option. But why would Microsoft choose to go this path? Well for starters, all Exchange servers, with the exception of the Edge Transport server role, can be identical. This would be in terms of hardware purchasing, maintenance, management, and configuration. Another benefit is the need for fewer physical servers, which in turn means fewer licenses and reduced rack space.
Client Access services provide authentication and proxy services in client connections coming from inside and outside a customer’s environment. The Client Access services in Exchange is primarily for end user devices (clients) connecting to their Exchange mailboxes using a number of supported protocols such as HTTPS, POP3, SMTP, and IMAP4. Outlook clients use MAPI over HTTP or Outlook Anywhere which uses (RPC over HTTP). The default in Exchange 2016 and 2019 is MAPI over HTTP.
Managed Availability was first introduced in Exchange Server 2013. It combines active monitoring and automated recovery for your Exchange Server workloads. Since it is not efficient to diagnose and try to identify the root cause of an issue, Managed Availability will just attempt to perform a recovery. This approach will primarily focus of availability, latency, and errors within a workload. There are two main services associated with Managed Availability:
There are three main components to Managed Availability: Probes, Monitors, and responders. We will take a look at each of these components individually.
Probes will collect the information from the different Exchange workloads. They come in three categories:
Monitors analyze the data that the probes collect. A determination is then made to verify if the component is healthy or unhealthy based on a set of rules. When an unhealthy state is determined, it can either try to automatically recover or it can escalate an issue for manual remediate by creating an event in the Windows Event Log. Monitors will log issues that require human involvement in the Microsoft.Exchange.ManagedAvailability\Monitoring crimson channel. They will not always initiate recovery or escalate when a single probe failure occurs since they have their own thresholds that need to be met before performing an action.
Responders perform automated actions when attempting workload recoveries. Responders can be throttled to guarantee a correct sequence of actions are performed that would not create other issues. Certain actions can be restarting services, fail over databases, initiate bugchecks, escalate event-log entries, plus much more. Responder actions can also include time delays and skipping certain actions to ensure other services and components will not be affected.
You can customize a probe, a monitor, or a responder by using an override when the defaults do not suit your organization. To modify the default Managed Availability settings, you need to utilize the Exchange PowerShell. You need to be familiar with the properties of the specific probe, monitor, or responder before making changes. As a best practice, I do not recommend that you implement overrides for Managed Availability unless a Microsoft support professional has instructed you to do so. Changes can take up to 10 minutes to take effect, or you can restart the Health Manager Services to implement immediately.
There are two types of overrides to accommodate specific and global customizations, including:
Local overrides. You can create and modify them on a specific server using the *-ServerMonitoringOverride cmdlets (*=Add/Set/Remove). They are stored locally in the Windows Registry under the following path:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\ExchangeServer\v15\ActiveMonitoring\Overrides\
Global overrides. You can create and modify them for multiple servers using the *-GlobalMonitoringOverride cmdlets (*=Add/Set/Remove). They are stored in Active Directory Domain Services (AD DS) under the container:
CN=Overrides,CN=Monitoring Settings,CN=FM,CN=Microsoft Exchange,CN=Services,CN=Configuration,DC=Adatum,DC=com
Within each component from Exchange, Managed Availability will give use Health sets and Health Groups. Each Exchange Server component that Managed Availability monitors has its own set of probes, monitors, and responders. These groupings are called Health Sets. To view a list of Health Sets, you can run the following command in the Exchange Management Shell:
Get-HealthReport –Identity <Server Name>
For a list of probes, monitors, and responders associated with a Health Set, you can run the following command in the Exchange Management Shell:
Get-MonitoringItemIdentity –Server <Server Name> -Identity <HealthSetName> | ft Identity,ItemType,Name -AutoSize
To view a list of all the unhealthy monitors for all the Health Sets on a server, run the following command in the Exchange Management Shell:
Get-HealthReport -Server <Server Name> | ? {$_.AlertValue -ne 'Healthy'} | % Entries | ? {$_.AlertValue -ne 'Healthy'}
There are also external views called Health Groups, which are rollups of Health Sets. Managed Availability can leverage a solution such as System Center Operations Manager when using the Exchange Server 2013 Management Pack to expose Health Groups is a clearer format. There are four main Health Groups:
The Microsoft Exchange Diagnostics Service works in conjunction with the Performance Monitor. Instead of creating custom data collection sets with the Performance Monitor, this service is a process that runs in the background and with gather and compile all relevant Exchange Server performance counters automatically and on a continuous basis. It will store up to 5GB of data for seven days. This allows administrators to troubleshoot performance issues without the need to collect new data in response to an issue. The amount of data can be adjusted by editing the Microsoft.Exchange.Diagnostics.Service.exe.config file that is located in C:\Program Files\Microsoft\Exchange Server\V15\bin. The section of the file to be edited is shown below:
<add Name="DailyPerformanceLogs" LogDataLoss="True"
MaxSize="5120" MaxSizeDatacenter="2048" MaxAge="7.00:00:00"
CheckInterval="08:00:00" />
The service will generate .blg files in the C:\Program Files\Microsoft\Exchange Server\V15\Logging\Diagnostics\DailyPerformanceLog folder. You will need to use the Performance Monitor to open them. There will be a large amount of data to view in these files so you have the ability to customize the data view. Run a PowerShell cmdlet similar to what is listed below to provide summary data about daily performance logs, including the oldest and newest records present
Import-Counter -Path ‘C:\Program Files\Microsoft\Exchange Server\V15\Logging\Diagnostics\DailyPerformanceLogs\*.blg’ –Summary
Use PowerShell to export specific counters to a separate .blg file so that you can view them more easily:
$PerfData = Import-Counter -Path ‘C:\Program Files\Microsoft\Exchange Server\V15\Logging\Diagnostics\DailyPerformanceLogs\*.blg’
-Counter ‘\\LON-EX1\MSExchange ADAccess Domain Controllers(*)\LDAP Read Time’
$PerfData | Export-Counter -Path C:\LDAPReadTime.blg
The Performance Monitor uses counters, event trace data, and configuration information to create what are called data collector sets. The Performance Monitor will analyze how your Exchange Server affects your computer’s performance. This tool is available on versions of Windows Server that are supported for Exchange Server. We will look at the individual counters recommended for CAS Monitoring in the next section.
Collecting performance data for CAS monitoring is essential during Exchange Server setup. In order to utilize the metrics collected from the Performance Monitor, you need to ensure you have created a monitoring baseline for comparison. A baseline includes the average performance metrics from a properly functioning operating system. In your performance baseline, you need to include the performance data for a full business cycle and take note of any peaks or troughs that were recorded in your data. When collecting this baseline data, you should be running the counters during working hours and times of high Exchange utilization. You should not include non-working hours or weekends if you usage will be a lot lower. Also, ensure you are not running any backups, or performing any updates, upgrades, or maintenance on your exchange servers during this time as it can greatly impact your collected metrics.
Next, you need to set warning and error level thresholds to ensure you receive warnings about any irregular data. Finally, you need to review the performance data that the Microsoft Exchange Diagnostics service has collected, and compare it to your recorded baseline.
Depending on what you are monitoring within Client Access services, you will need to track and implement multiple counters depending on if you are monitoring front-end or backend Client Access mechanisms. The front-end components perform your authentication and proxy of HTTP traffic to the backend components, which then communicate with the mailbox database. Here are some of the performance counters relevant to the front-end:
MSExchange HTTP Proxy. The counter associated with this group is Proxy Requests/Sec. This counter will show you the number of proxy requests that are serviced each second.
RPC/HTTP Proxy. The counter needed is the Number of failed backend connection attempts per second. This counter will show you the rate of RPC proxy attempts fail to establish a connection to a backend server. This counter is not necessarily needed when utilizing only Exchange Server 2019. This should be used in the event you are using a coexistence scenario where the Exchange and Outlook versions do not support the MAPI/HTTP protocol.
MSExchange Authentication. The counter needed is Total Authentication Requests. This counter shows the number of authentication requests that have been serviced each second.
When monitoring the backend Client Access components, you will be monitoring ASP.NET and its applications, as well as MSExchange web services. ASP.NET and ASP.NET applications counter groups will allow you to monitor the response time and frequency at which applications have had to restart. This will help you verify the health of your services.
ASP.Net. There are four counters you will need to monitor your ASP.NET health:
ASP.NET Applications. The counter that is recommended is Requests in Application Queue. This counter will show the number of requests in the application request queue. The maximum value is 5,000. The server gives a 503 error if the counter exceeds that value.
When dealing with MSExchange web services, we are looking for response times associated with our web services. Outlook on the web, Exchange ActiveSync, the Offline Address Book downloads, and the Availability service are all components that require monitoring. Any time the value of these counters differ from our performance baseline, clients are most likely experiencing slower than normal server response times.
MSExchange OWA. The counters recommended are Average Response Time and Average Search Time.
MSExchange ActiveSync. The recommended counter is Average Request Time. The counter will show the average time that has passed while waiting for a request to complete. This counter determines the rate at which the Availability Service requests are taking place.
MSExchange Availability Service. The recommended counter is Average Time to Process a Free Busy Request. The purpose of this counter is to show the number of requests serviced per second.
I hope you have found this article helpful in regard to the built-in tools available for Exchange 2016/2019 CAS monitoring. For more information, you may refer to the Microsoft documentation, other ENow Software blogs, ENow's Exchange Monitoring Solution, or a Microsoft Consulting Partner.
On-premises components, such as AD FS, PTA, and Exchange Hybrid are critical for Office 365 end user experience. In addition, something as trivial as expiring Exchange or AD FS certificates can certainly lead to unexpected outages By proactively monitoring hybrid components, ENow gives you early warnings where hybrid components are reaching a critical state, or even for an upcoming expiring certificate. Knowing immediately when a problem happens, where the fault lies, and why the issue has occurred, ensures that any outages are detected and solved as quickly as possible.
Access your free 14-day trial of ENow’s Exchange Hybrid and Office 365 Monitoring and Reporting today!

Jonathan is an Information Technology consultant and instructor that specializes in migrations, security audits, new Microsoft technology implementations, and support contracts for Microsoft technologies. Jonathan also has expertise in Office 365 Services including, but not limited to, Azure Active Directory, Exchange Online, Skype for Business/Teams, SharePoint Online/OneDrive, Microsoft Azure/Office 365 Security and Compliance features including alerts, permissions, information classification, data loss prevention, information governance, threat management, data privacy, and reporting.

On-premises Exchange servers are still a thing, and with future versions of Exchange coming...

Exchange Server has two core components. First, there is the mailbox component, with all the...