IT/Dev Connections 2015: The Session Run-Down

With IT/DEV Connections less than two weeks out, I found myself getting anxious to attend these...

As reported earlier, Office 365 was recently hit with a widespread issue. According to the case details that Microsoft posted to its service dashboard, the problems started around 6:15 PM (EST) on July 15 and were solved by July 15 at 9:30 PM (EST).
That is a little over three hours that customers were experiencing all sorts of issues! Even though it's unlikely this outage alone will affect Microsoft's 99.9% uptime on a yearly basis, the impact and inconvenience on the customer base is big. While Microsoft does a terrific job running Office 365, this wasn't the first outage, and it likely won’t be the last, either.
As the noise about this outage grew stronger on social media, Microsoft first updated its Service Dashboard about this problem at approximately 7:28 PM (EST) — 1.5 hours after people began reporting connectivity issues. Looking through my Twitter feed, it seems that some customers reported problems even earlier than that, which aligns with the data I pulled from our own production environment:
Microsoft's investigation revealed that a 'bad update' caused a higher-than-normal load on the Active Directory infrastructure, which, in turn, prevented users from authenticating to the service. Because of how authentication works in Office 365, this meant that not all users were impacted at the same time. For instance, if you were previously authenticated in OWA (and thus had a valid token), chances were you could still work without any problems.
However, if you tried opening a new session in OWA or Outlook, you could not connect. Later, mail delivery issues were added to the list of symptoms, which made the effects of the outage just a little more painful — even if you were one of the happy bunch that was still connected.
Let's start off with something positive about this outage: Even though one or two hours passed between some updates, Microsoft communicated quite transparently about the problem. That is a good thing. However, being in the dark for 1.5 hours before the first service update is not a good spot to be in as an administrator. Social media proves to be very useful (just look at how many people are complaining about issues), but it doesn't provide a very definitive or personalized answer to how your tenant is doing at that moment.
Does this mean there's nothing you can do? Of course not! Since 2012, ENow ships Mailscape 365, a monitoring solution for Office 365 and related components.
For many organizations, monitoring cloud services is often an afterthought. Most don't think it's worthwhile to monitor ‘the cloud’ because the redundancy and Service Levels that vendors like Microsoft offer are ‘good enough.’ That sentiment usually lasts until the first service problem or outage. Despite the fact that you cannot do much about an outage in Office 365, it doesn't mean you have to sit still and do nothing. Especially with cloud services, it’s important that you, as an IT organization, ‘manage’ the outage to the best of your abilities. You should proactively communicate with your user base and management. But how can you do so if you rely solely on a dashboard that’s only updated hours after the problem first started? Exactly: You can't!
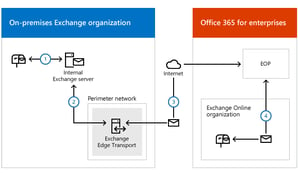
Supporting a cloud-based service or hybrid deployment is very different from supporting an on-premises-only environment where you have almost total control over all components from beginning to end. But as soon as cloud-based systems are involved, the playing field changes dramatically. Suddenly, servers don't matter as much, if at all. Instead, the service you’re buying (access to email, ability to send/receive emails, etc.) is the focus and not the systems that allow you to do it; that’s the responsibility of the vendor providing the service.
This means that traditional monitoring (server components, resource usage, etc.) are not enough anymore. So how do you gain more visibility into your service? The answer is by focusing on what an end user can do and proactively testing that. One way to do that is by using synthetic transactions that mimic an end user's interaction with the server. These transactions allow you to monitor whether or not the action succeeded and give you the ability to measure how long it took to perform a certain task.
Based on the recent outage, I took the liberty to look at our own production system. What follows is a chronological overview of how Mailscape 365 detected and reported the issues in Office 365. This will allow you to see how our monitoring engine was able to detect the outage early on by analyzing a set of synthetic transactions and measurements of our tenant. Although we have seen some intermittent issues prior to these events, I chose to focus on the time span that aligns with what Microsoft reported. I also did not include all events and instead focused on the ‘problem’ areas mentioned earlier (OWA, Outlook, Mail Flow):
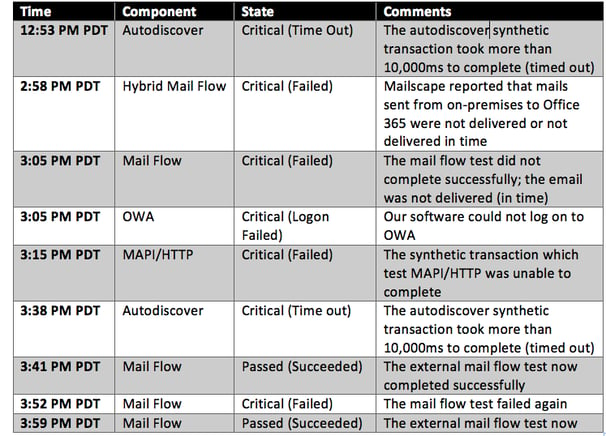
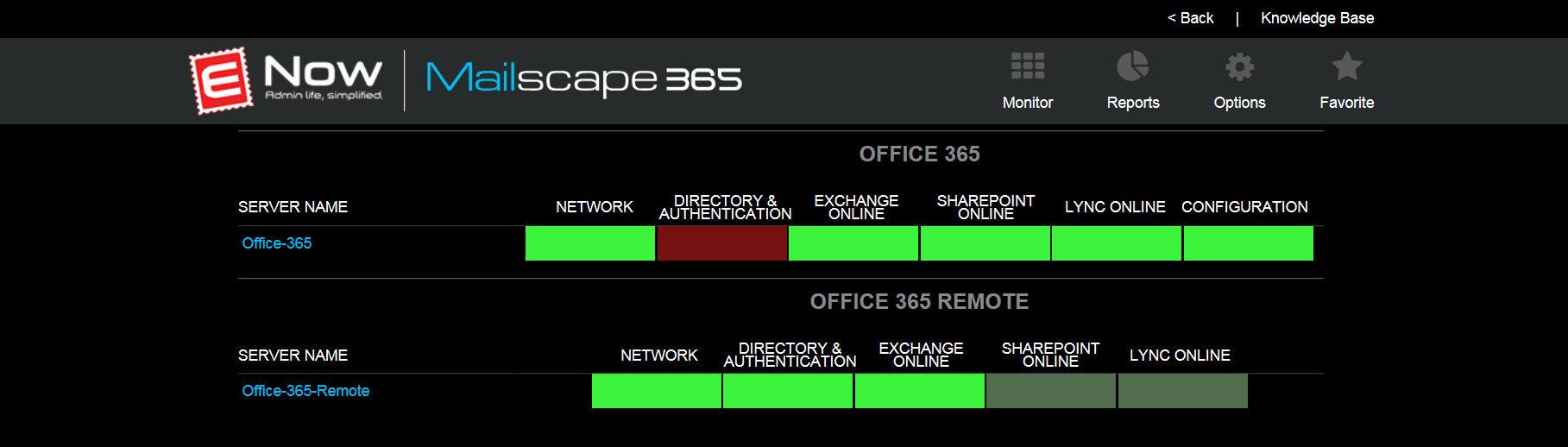
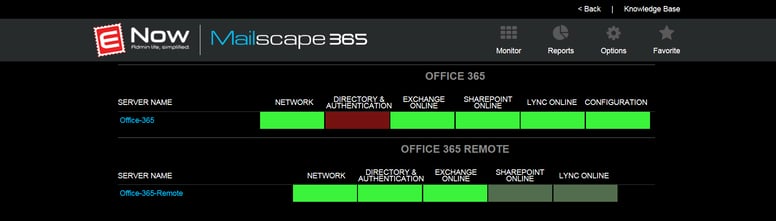
As you can see, Mailscape 365 picked up on performance issues at 12:53 PM (PDT). If those events are isolated, it sometimes points to a temporary glitch in connectivity to Office 365.
However, from 12:53 PM (PDT) onward, we were already seeing lots of (intermittent) failed transactions. Often, such behavior can be a signal for worse things to come. Given that our IT team was already alerted at 12:53 PM (PDT), they knew something was going on more than two hours before Microsoft officially acknowledged there was a problem. The early warning allowed our internal IT department to broadcast a message (not via email!) informing users there was a problem, they were aware of it and that they were actively working on it with Microsoft. Understandably, they weren't too happy about the outage, but at least they were fully informed and could trust that the IT department knew what was broken and how long it had been broken.
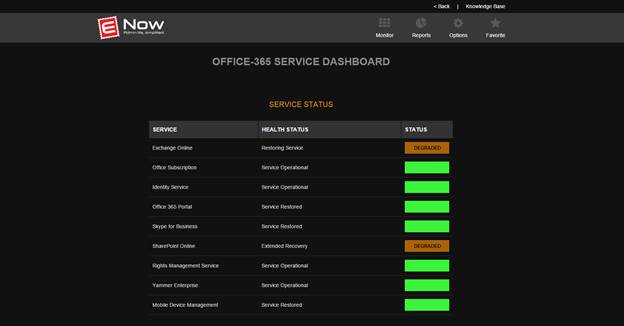
Because Mailscape 365 monitors Office 365 at different levels, we were able to highlight problems as granular as the protocol level, which proved useful because it immediately confirmed that the problem affected all client protocols — ruling out the option to advise people to use a different client instead. Because ENow is part of the Technology Adoption Program (TAP), we were also able to incorporate a view of the service health dashboard in our solution:
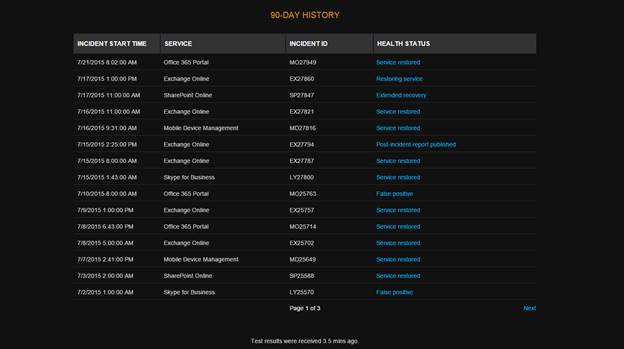
Even though the dashboard might not be an up-to-the-minute view of what is going on, it does provide additional and useful information on the outage. Having it at your fingertips means you don't have to separately log into the portal to follow up on Microsoft's communications. Not only does it save you time, but it also removes the need to grant people certain administrative permission to your tenant.
Mailscape 365 also monitors on-premises components (such as AD FS, DirSync and Exchange). This is important because more than half of the problems reported to Office 365 find their origin in a problem on the customer side, not Office 365! As these on-premises tests were still succeeding, our customers knew their own systems didn’t cause the problem, saving them time troubleshooting the issues and trying to pinpoint the root cause of the outage.
Why is this important you ask? Well consider the same symptoms: users cannot log in to Office 365-related services and they start calling into the helpdesk. If the Mailscape 365 dashboard shows that the various Exchange Online tests and the AD FS synthetic transactions are failing, that immediately tells the IT team there might be a connected problem and triggers them to look into AD FS.
All this goes to prove that monitoring cloud-based services, like Office 365, is valuable at different levels. Not only does it help you determine if the problem originates on-premises or in the cloud, it also allows you to detect problems early on so you can better manage the outage (and impress your management)! Who wouldn't like that?