Planning for Public Folders in Exchange 2013

When designing for a migration to Exchange Server 2013, chances are you’ll have to deal with public...

Recently, one of my customers reached out to me stating they were having trouble delivering emails due to SPF failures. While it’s not uncommon for SPF checks to fail (you don’t want to know how many organizations struggle implementing SPF records correctly!), I was a little surprised. After all, the customer had successfully implemented SPF records for quite some time now, and rarely ran into issues with it. In fact, they are quite the example for some of my other customers as their SPF policy is set to a hard failure. Needless to say: a lot of effort went into it, to ensure their SPF records were correct/up-to-date/etc. However, that's not the point here. What follows is an overview of what we've discovered during our troubleshooting. To me, it revealed some interesting routing logic in EOP –some of which is barely (not) documented.
I would like to thank Microsoft Support for their assistance with this issue. Although we might not always have agreed on the approach/outcome, I'm a firm believer that "sparring" sometimes leads to better solutions; as was the case here. In particular, I would also like to thank Scott Landry for his help and input during our endeavour.
To understand the issue, you will need some background information first. This customer is in process of moving to Office 365. They intend to use a hybrid configuration and already ran the Hybrid Configuration Wizard a while ago.
In an initial phase, they will be running a centralized mail flow setup (CMT). This is also reflected by the hybrid configuration; the HCW had configured an Outbound Connector in Office 365 with the parameter “RouteAllMessagesViaOnPremises” set to True. When set to $True, it basically means that all messages should be routed via the on-premises Exchange Servers –but you already got that from the attribute's name, didn't you?

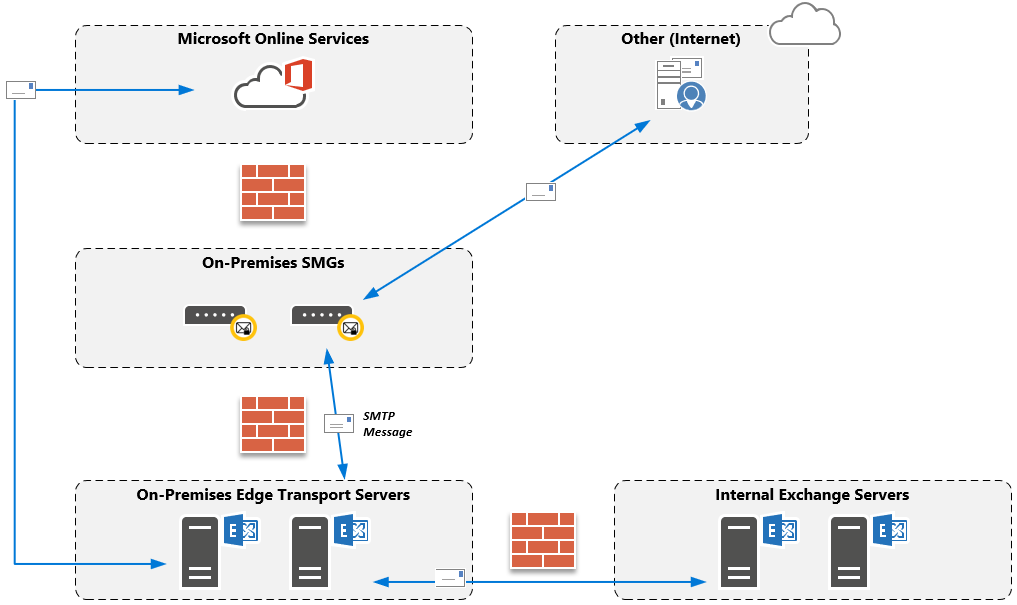
Keeping the above in mind, one would expect messages to be routed as depicted in the image below:
An internal recipient sends a message to an external recipient. For sake of brevity and relevance to this case, we will just be looking at messages originating from on-premises Exchange servers; the customer does not have any mailboxes in Exchange Online yet.
Nothing exciting happening here. This is all very simple, and basic email routing... However, looking at the headers of messages that failed SPF checks, we noticed something weird in the Authentication-Results: the IP address of the sender was not one of our on-premises gateways, but one of EOP’s many IP addresses.
spf=fail (sender IP is 40.107.0.96)
After a while, we established some sort of pattern and noticed that the SPF checks only failed for specific recipients/domains –all of which happened to use either Exchange Online Protection to secure their on-premises mailboxes, or mailboxes in Exchange Online. Oddly enough, not all recipients using EOP were "affected".
A preliminary analysis (with Microsoft support) revealed that messages were indeed routed through EOP and, because the customer had not yet updated their SPF records to include EOP as a permitted sender, those messages were failing SPF checks; as one would expect. You could argue that updating the SPF records at this point would solve the issue, but the more interesting question is: why are messages routed through EOP in the first place? Following the logic outlined in the image earlier, there should be no reason for those messages to appear to be sent from EOP. If anything, the last hop between the recipient and our environment, should be the on-premises mail filtering appliances.
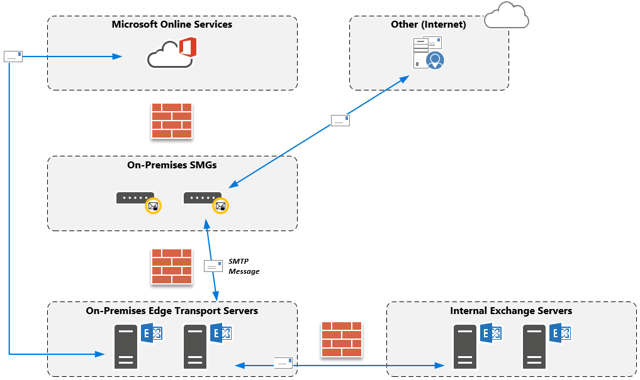
Given the information we gathered, the routing of messages looked something like the following. Note that this only applies to recipients behind EOP:
First, we looked at the hybrid configuration. We believed it might be acting up and perhaps messages were wrongly routed using our hybrid connector. However, we quickly realised that was not the case; the Edge Transport servers aren’t connected to the Internet just yet, and thus could not even communicate with Office-365. Even more so, our internal send connector configuration wouldn’t even allow the "hybrid connectors" to be used. The cost of the connector between the internal Exchange Servers and the Edge Transport servers was higher than the cost from the internal Exchange servers to the hygiene appliances. As such, the Edge Transport servers were effectively bypassed.
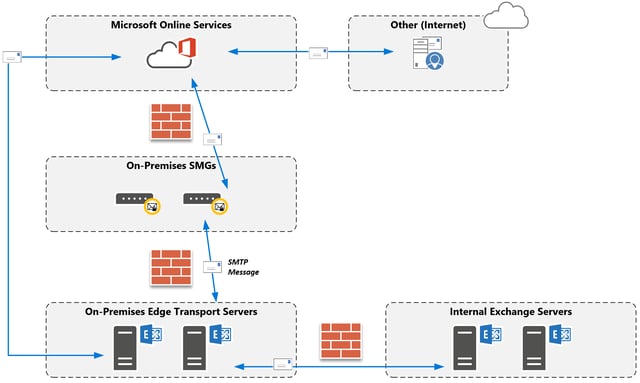
More importantly though, the majority of mail flow to other recipients remained unaffected. A second look at the headers clearly showed that messages were flowing through the on-premises appliances:
Thus the question remained: Why was EOP “taking over” routing for some messages?
Fast forward a few hours and we finally got an answer to our question. Before diving into the details, consider the following circumstances:
So, what’s the issue? In short, when EOP receives a message through a connection that matches the criteria of one of the Inbound connectors in your tenant, it then will ‘attribute’ that message to your tenant: EOP will deem the message as destined for your tenant before applying additional routing logic/decisions. Note that this only happens when the message is received by EOP in "your" Exchange Online forest. If a message is received by EOP in another forest, the message will just be routed as you'd expect.
Because of this logic, messages that are attributed to your tenant are first routed to your tenant, before being routed onwards to their destination (other customer tenants). When this happens, EOP will show as the last hop. This is also what the recipient's filtering solution (in this case, always EOP), will use to perform SPF checks etc. If you do not add the SPF details for EOP to your SPF-record, an SPF failure is triggered. Depending on your SPF record configuration, the customer’s spam filtering logic and the position of the moon and stars, your message might end up in the Inbox, Junk Mail Folder, Quarantine or even in limbo (if a rule is set to drop such messages).
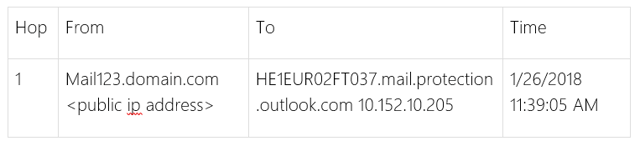
So, why did messages get attributed to our tenant you may ask? The on-premises mail filtering appliances all use an FQDN in the likes of “mail123.domain.com” or “mail678.domain.com”. Because these hostnames match the wildcard on the Inbound Connector, EOP attributes those messages to our tenant. Pretty straightfroward, no?
When we ran the HCW, it successfully created a new Inbound Connector and configured the TLSCertificateName-property to be *.domain.com, as depicted below:
TlsSenderCertificateName : *.domain.com
Although it is not uncommon to use a wildcard certificate, it is odd to see the HCW used a wildcard. None of the on-premises Exchange servers are configured with a wildcard certificate. Instead, they all have a certificate “hybrid.domain.com” assigned to the SMTP service. During the wizard, hybrid.domain.com was also the certificate that was selected, and the SMTP-endpoint that was configured for mail delivery.
As it turns out, the wizard will automatically updates/changes the TlsSenderCertificateName from the Subject Name (hostname) to a wildcard for you, to help prevent other issues. One of them being related to the following article.
Most customers do not have their certificate subject name registered as an accepted domain. If the wizard would not step in at this point (and configure a wildcard instead), customers would not be able to relay through EOP. However, once you end up with the mail flow scenario like described earlier, mail flow could break.
While I understand the why Microsoft would choose to maintain this logic, I’m a bit disappointed by how badly communicated/documented it is. First of all, I believe the HCW should warn you about this. At the very least, it should inform you to register your hostname, or check it for you. Given its connectivity to Office 365, the HCW could do that! In our case, however, we did not get a warning, advise or anything of the sorts.
Second, I believe a lot more organizations are currently in this situation than one might think. The majority probably don't even know, because they probably have updated their SPF record. While that ensures the SPF checks “pass”, the odd routing behaviour still exists, remains unpredictable and varies from one recipient domain to another... Some might not care, others might.
There's more than one way to shine a penny. A quick win is to disable the connector in Exchange Online/EOP. While this seems to solve the issue, it merely shifts the problem to later. If you already have mailboxes in Exchange Online, it will also break your hybrid mail flow. So, not the best option!
Another option is to update your SPF records and let EOP take away the routing. While this removes the symptoms of messages not arriving at their destination, this is not solving the actual "problem" in my opinion. But if it works for you, it works for you. Especially if you are looking to send outbound email through EOP in the (near) future, adding the SPF details seems like a sensible thing to do. Really!
Ideally, you would add the hostname (on the cert) as an accepted domain to your tenant and then re-run the HCW. This triggers a different logic, and the Inbound connector will be updated to reflect the actual hostname of your transport certificate. This assumes that your on-premises appliances do not send messages out to the internet using the same hostname as your hybrid SMTP endpoint (e.g. hybrid.domain.com). If that were the case, this would not change anything for you.
If you cannot run the HCW, you can also manually update the Inbound connector in Office 365. Just remember that you will probably want to run the HCW again at some point in the future, and you best not forget to register the hostname as an accepted domain regardless.
In our case we couldn’t update our SPF records just yet. This surfaced the odd routing logic upheld by EOP. While updating SPF records seems like a simple task, it does require a bit of planning if you have an elaborate setup (and if you are heavily regulated!). But that was not the only reason. As we were still in the process of setting up Office 365, we had not (yet) received all approvals to go “to the cloud”. Consider the tenant setup to tip our toe in the water before going “all in”.
The latter is also the issue we had while talking to Microsoft when troubleshooting this problem. For them the solution was simple and a quick fix, and many engineers we talked to could not phantom why we pushed back on this change. Technically, they are 100% correct. For this customer, however, as a heavy regulated organization, it was not only a technical issue. They just cannot make some changes on the fly (even emergency changes like this), especially because in this case also domains from other regions were involved. Some of these regions are not even allowed to move to “the cloud” just yet… The joys of regulations.
I understand why Microsoft does what it does, but sometimes metrics don’t show the entire picture. Now that I know the logic behind some of the decisions in the HCW, I can keep it in mind for future deployments. I’m not asking Microsoft to update the HCW per se. If the metric show that we are merely a corner case, I'm happy to accept that. However, I firmly believe that some more elaborate documentation or a FAQ wouldn’t hurt.
What’s your opinion? Have you run into this issue before? What’s your take on pre-emptively registering the SPF records and/or the EOP routing logic? I’d love to hear from you!


