Office 365 Monitoring: Exchange Online Outage February 3, 2021
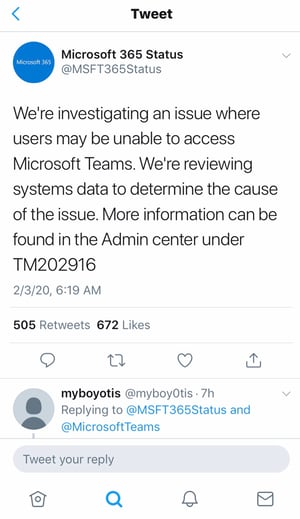
On February 3, 2021 at ~10:45 pm UTC, Microsoft reported an issue that was causing some users in...


This is a quick post to talk about the Microsoft Teams outage that occurred today, February 3rd, 2020.
At ~1:15pm UTC (6:15am here in the Mountain time zone for me), it was noticed that users were unable to sign into Microsoft Teams.
It was widely reported on Twitter that users who were signed in could continue to work within Microsoft Teams but users who weren't signed in or restarted Teams could not successfully sign-in.
In addition, some users reported being able to sign-in but not able to see chat history as well as other features not working like the ability to dial-in to a meeting.
Many turned to twitter and soon found that many IT Pros were complaining.
Microsoft came back with the following explanation of the outage:
Root cause: An authentication certificate expired, impacting any user with an expired authentication token or any user trying to login and authenticate from a logged out state.
Microsoft implemented a fix and for most people, sign-in issues were resolved by 5-6pm UTC (10-11am Mountain).
Side note: If I'm honest, I really want to make a joke that Microsoft Teams like many in the United States was suffering from the day after the Super Bowl lack of productivity but I'll try to stay focused.>
That's all well and good that the issue is fixed but it has to be asked, how does a certificate expire, and no one notices until a global outage happens? For many of us, we've been there. In our own companies we have forgotten to look at the certificate's expiration date and found it once the outage occurs. When it's impacting just our users, it's still not ok, let alone up to 20 million (reported Daily Active Usage of Teams) users. Hopefully Microsoft will learn from this and improve their operations.
There are scripts that can report when a certificate is expiring and can alert the proper group(s). Everyone should have this as part of their run books when certificates are used.
All of that said, as organizations are ever increasingly looking to move their productivity tools to the Cloud, outages like this will give them pause. Mainly because it is out of their control. On-premises systems still are susceptible to outages, but people always feel better if they can control the situation. It's human nature to want to be in control. The real question is whether this outage (or any other Cloud outage) is enough to outweigh the benefits of the Cloud as a whole and to give up that control?
We saw a different outage last October with Office 365. What's acceptable to an organization in regard to outages? Once a year? Twice? Never isn't a real answer as all systems can have an outage at some point.
As we move to the Cloud, most providers only provide a 99.9% uptime SLA commitment (just shy of 9 hours of downtime in a year for a particular service). Organizations will need to answer whether they want to keep these services on-premises and invest the money to properly make a system redundant or if the random, short outage is acceptable. For really critical systems, organizations spend more money to make them more resilient. It's a type of logarithmic curve at some point. The amount of money an org must spend in order to reduce the risk of downtime by a fraction becomes quite high as you get past 99.9% uptime. What's it worth to you? What's the impact of an outage on the bottom line for your organization?
Interested in learning more about the SLA commitment? Check out this article by Tony Redmond.
I'm curious on your take about this outage. Does it give you pause when considering Microsoft Teams? Are you still all in? Engage with us on Twitter at @enowconsulting. Let us know your thoughts!
ENow’s solution is like your own personal outage detector that pertains solely to your environment. ENow’s Office 365 Monitoring solution monitors all crucial components including your hybrid servers, the network, and Office 365 from a single pane of glass. Knowing immediately when a problem happens, where the fault lies, and why the issue has occurred, ensures that any outages are detected and solved as quickly as possible.
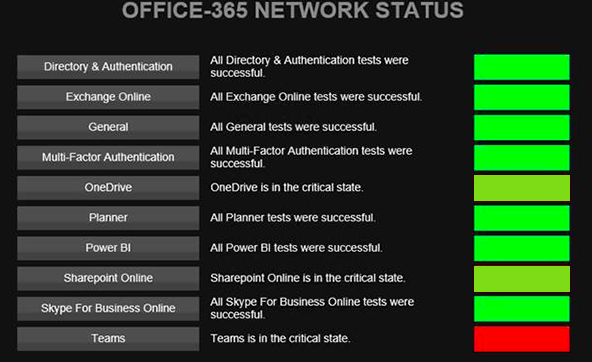
In the case of February 3rds outage, the admin center gave limited information on the scope of the problem and which subset of users were affected. This causes many to turn to twitter and start crowd surfing. In contrast, ENow's OneLook dashboard gives customers a single location to look to easily pinpoint the source of the problem. By doing so, IT is able to communicate the issue to their end users before their end users start flooding the help desk.
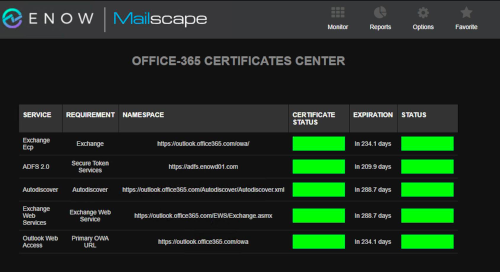
This outage proves that something as simple as a certificate can get the best of us, even Microsoft. While Microsoft's certificates are really only useful to them and they are ultimately responsible for keeping them up to date. In Hybrid scenarios, there are still a variety of certificates that IT Pros are responsible for including: Exchange, ADFS, and Autodiscover. Lapsing on these certificates can surely cause an outage, resulting in poor end user experience. As you can see below ENow's dashboard can monitor certificates in a single place, and alerts can easily be configured to notify appropriate team members as they near their expiration date