There’s a moment many Exchange admins know well: a call from the helpdesk, an upset team in finance, and the first question is “How long has this been going on?” The answer is usually uncomfortable because the problem existed long before anyone noticed.
That’s often the real issue with Exchange monitoring: not the outages that trigger immediate alerts, but the silent failures that creep in, escalate undetected, and only become visible after the damage is done. These gaps are the Exchange monitoring blind spots.
Before diving into the seven most common ones, it’s worth pausing to ask the fundamental question: how critical is email to your organization? In most organizations, mail flow isn’t a nice-to-have communication feature. It’s a business-critical infrastructure. Contracts, customer inquiries, supply chain communications, and internal approval workflows: all of it runs through Exchange. Disrupted mail flow isn’t an IT problem. It’s a business problem. Your monitoring posture should reflect that.
This article is the first in The 7 Exchange Monitoring Blind Spots Series, series examining the operational blind spots that allow Exchange problems to remain hidden long before users begin reporting them. In this first installment, we’ll focus on alerting gaps, ownership failures, and why infrastructure availability alone does not guarantee a functioning user experience.
Blind Spot #1: The Gap Nobody Sees - Because Nobody’s Looking
The Technical Alerting Problem
Imagine your Exchange server begins delaying messages at 11:30 PM, causing queues to build up. By 6:45 AM, the first employees arrive, and the mail flow has been disrupted for seven hours.
This isn’t just a hypothetical scenario; it’s a recurring pattern driven by Exchange monitoring systems that fail to alert anyone capable of responding. Many teams view monitoring as merely a technical process: gather metrics, set thresholds, and send alerts.
Exchange Monitoring Fails Without Ownership
What’s often missing is organizational clarity. When an alert fires in the middle of the night, who is notified? Through which channel? Is there an on-call rotation, and is the person authorized and able to act? These questions are organizational but inseparable from the monitoring itself. An alert sent as an unread email isn’t truly an alert. It's just a log entry.
Defining an Effective Monitoring Response Model
Notification Channels
First, consider notification channels: relying solely on email for alerts creates a single point of failure, particularly if Exchange isn’t delivering mail. A wise approach combines push notifications via mobile apps, SMS gateways, or messaging platforms like Teams, along with automated escalation levels.
Responsibilities & Accountability
Next, define responsibilities:
- Who is the main contact for Exchange alerts?
- Who serves as the backup?
- Is there an on-call rotation, and if so, during which time frames?
Response Thresholds & Tolerance
In organizations where email is vital 24/7, on-call coverage over weekends and holidays is essential for risk management. In other settings, a clear escalation plan for the next business day might be enough; either way, this should be a deliberate, documented, and communicated decision. Lastly, set thresholds: not all five-minute queue delays need urgent midnight alerts, but an hour-long mail flow standstill does.
Proper calibration is key. Too many alerts cause fatigue, too few risk prolonged issues, like the seven-hour gaps mentioned earlier. More on this will be covered in a future article.
Blind Spot #2: Ping Responds - But Exchange Doesn’t
Infrastructure Availability Is Not Service Availability
The server is reachable. The OS responds. Ping comes back. Everything is green.
And yet users can’t connect with Outlook.
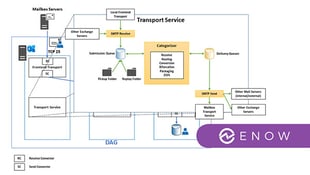
Ping-based checks do not constitute comprehensive Exchange Monitoring. They only confirm the presence of a host on the network, not whether Exchange services are operational. A server might be fully accessible from the OS perspective, yet individual Exchange services could be blocked or unresponsive internally.
Microsoft Exchange Requires Protocol-Level Monitoring
What truly matters are functional, application-level tests across all protocols your environment employs. This includes:
- MAPI over HTTP for Outlook
- Exchange Web Services (EWS) for calendar sharing and third-party apps
- AutoDiscover
- OWA
- ActiveSync
- POP3 and IMAP4, depending on configuration
Authentication Must Be Part of the Test
Crucially, each test must include authentication; simply verifying endpoint responsiveness is meaningless if login failures occur silently due to issues like expired tokens or DNS problems.
This principle extends across all protocols: infrastructure monitoring and application monitoring are distinct. Relying solely on infrastructure checks provides an incomplete picture. Effective monitoring involves automated, periodic tests for each protocol, such as logins, calendar queries, and mailbox access, on a configurable schedule with defined response expectations. This approach ensures that deviations from expected behavior trigger alerts before users are affected.
Conclusion
Many Exchange monitoring failures are not caused by missing metrics alone. They happen because organizations mistake infrastructure availability for operational visibility.
A healthy ping response does not guarantee Outlook connectivity. A delivered alert does not guarantee someone saw it. And an HTTP response does not confirm that users can successfully authenticate, access mailboxes, or remain productive.
The first two Exchange monitoring blind spots share a common theme: problems often exist long before anyone realizes users are impacted. Effective Exchange monitoring requires more than basic server checks. It requires proactive alerting, protocol-level validation, synthetic transactions, and clearly defined operational ownership.
ENow helps organizations monitor Exchange Server, Exchange Online, and hybrid Exchange environments through a single monitoring and reporting platform. Synthetic transaction monitoring, proactive alerting, Outlook connectivity testing, OWA validation, and protocol-level visibility help IT teams identify issues before users become the monitoring system themselves.
But validating client connectivity is only part of the challenge.
In the next article in this series, we’ll examine why hybrid Exchange mail flow failures are often far more difficult to detect, especially when telemetry delays, asymmetric routing issues, and Exchange Online visibility gaps begin masking the real root cause.


-1.png)